We Now Have Search
When I switched from using Wordpress to Hugo I thought I was giving up on search functionality on this blog. I just discovered recently I was wrong! After coming across the post Fast, keyboard optimized search for Hugo I saw that it can indeed be done. The trick to get Hugo to output a single .json file containing all of the sites textual content. This will serve as the “dictionary” for our search engine. We then use Javascript running on the clients browser to download this .json dictionary, index the data, and then provide search functionality to the user.
The above-linked forum post used the Javascript library fuse to provide the search functionality. However I found this library to be somewhat slow given the large amount of text it had to index (2.4MiB in this case). Instead, I settled on the Javascript library flexsearch which was much faster and gave me greater control over how the text was indexed. The demo of the new search feature is shown in the .gif below:
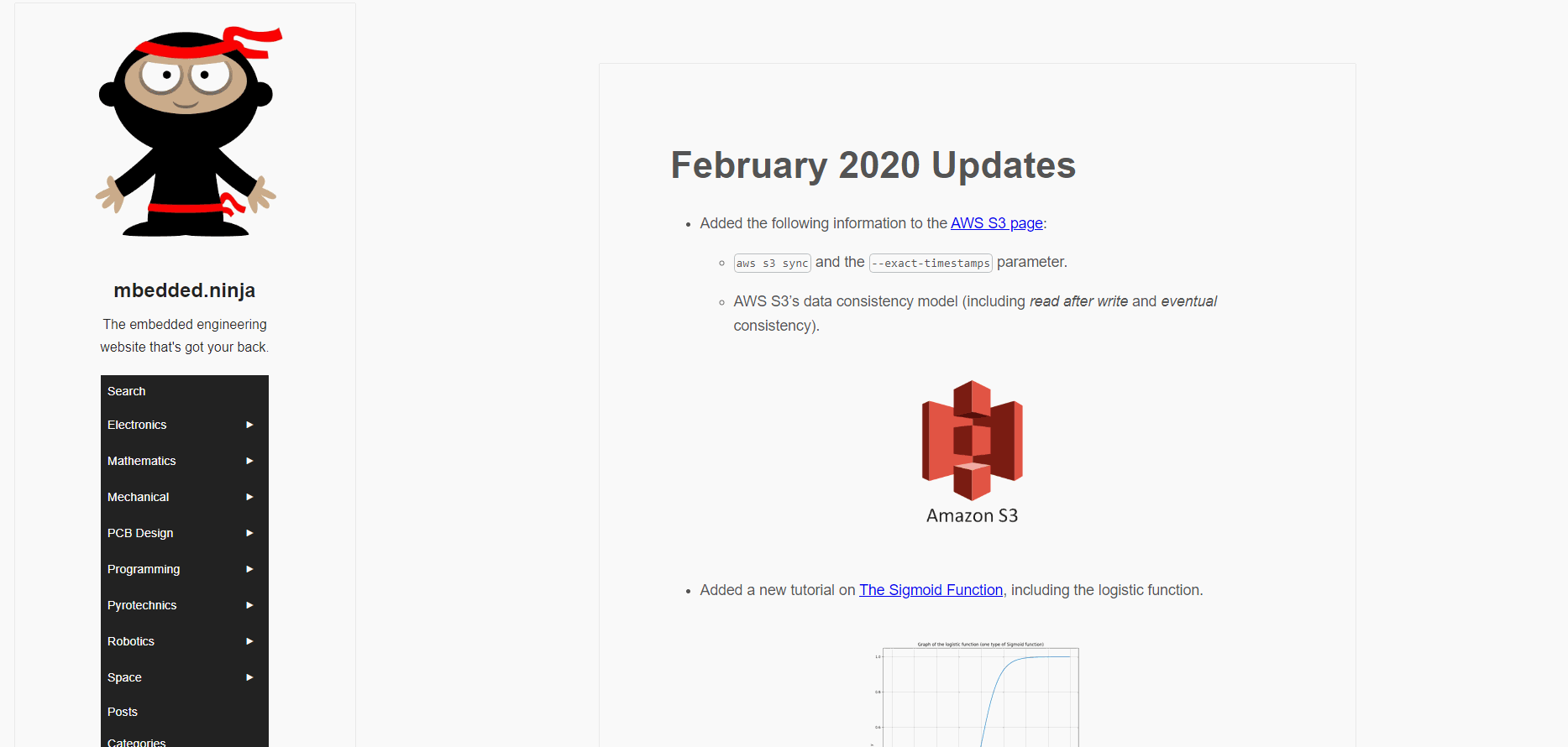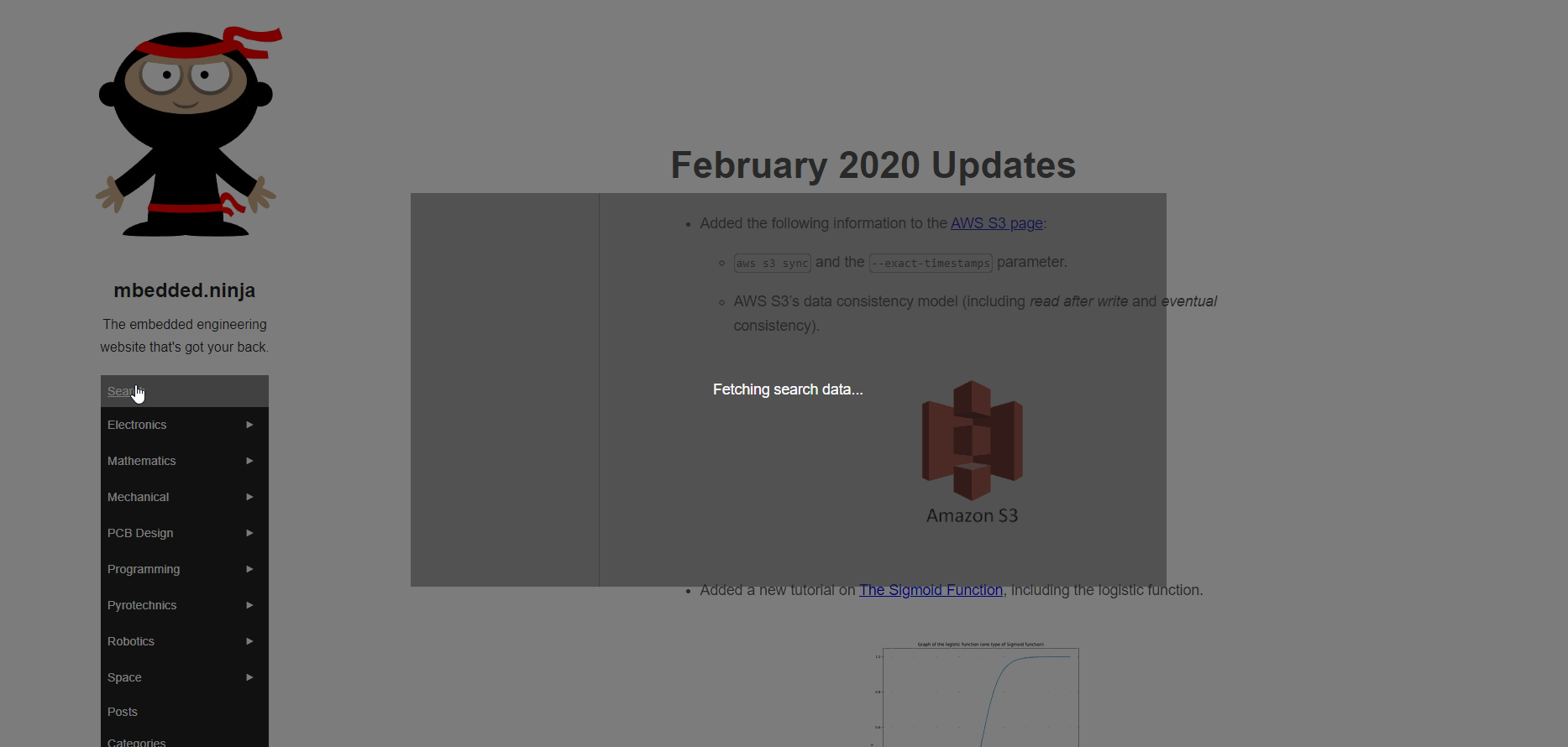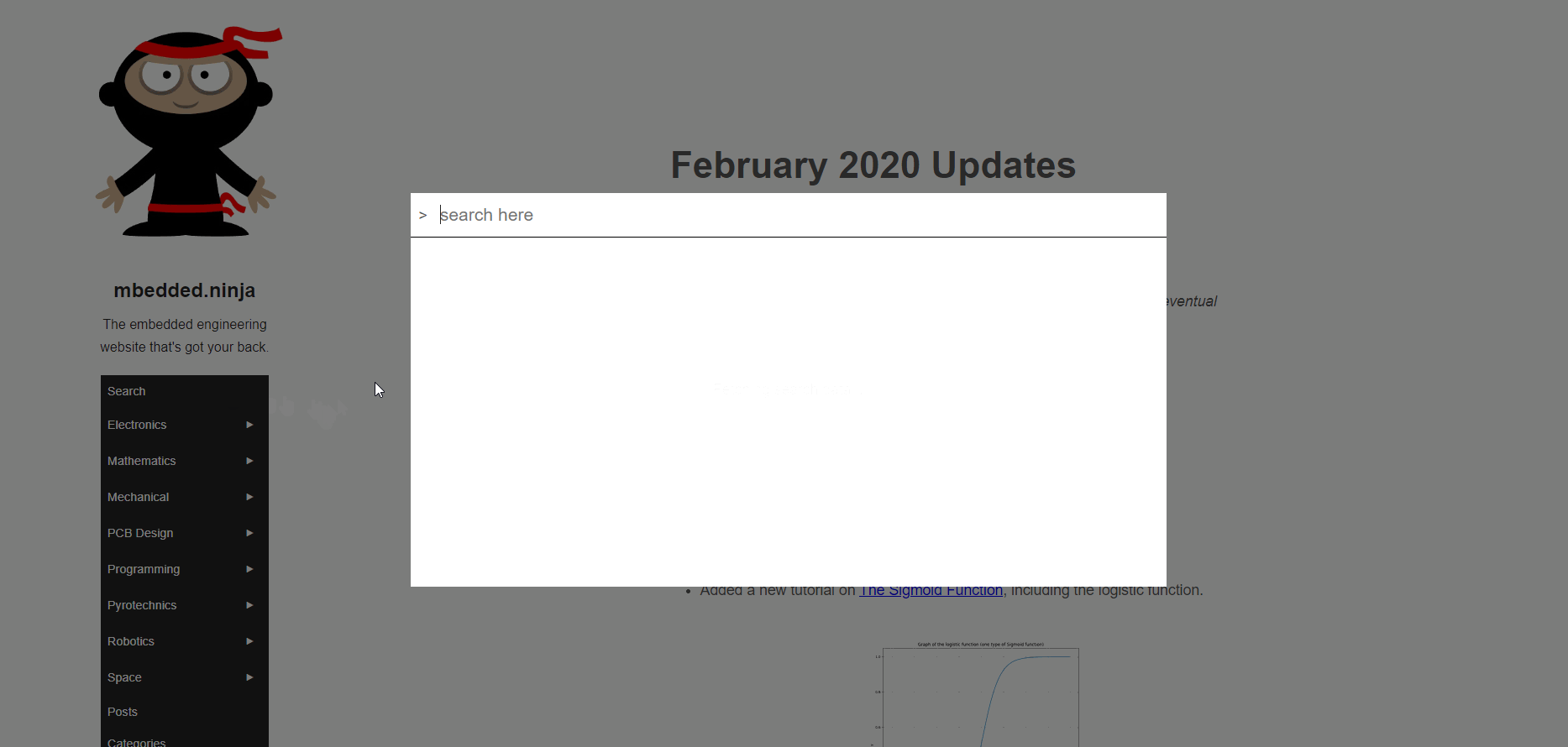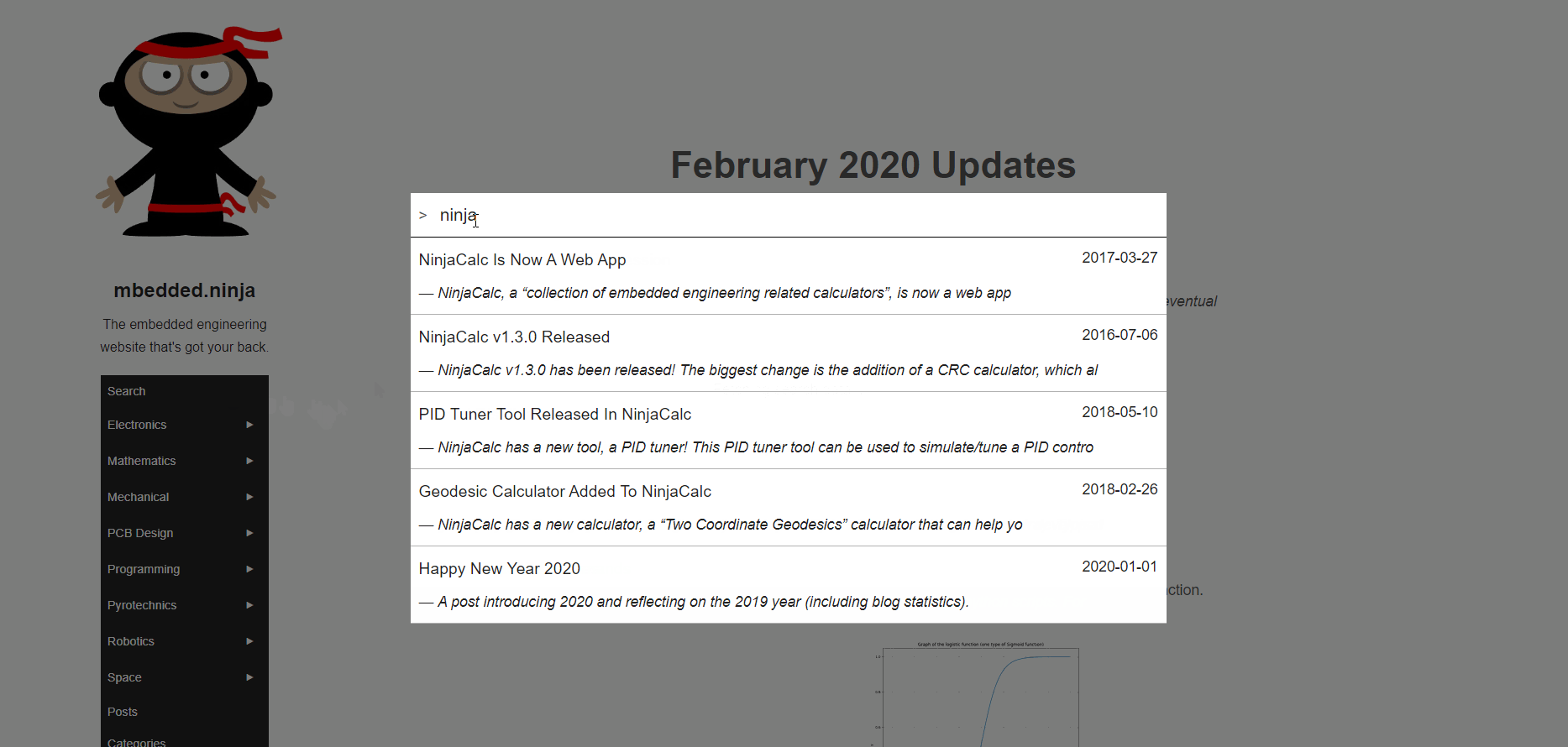
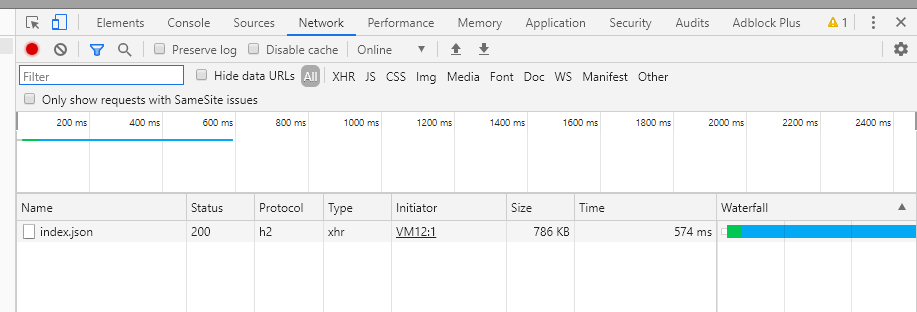
The screenshot below of the Network panel in the Chrome Developer Tools shows the time it takes to download the blog’s search dictionary (which is called index.json) to the client’s browser. The HTTP2 protocol automatically compresses the 2.4MiB file down to only 786kiB (which is great, it means I don’t have to implement compression myself, and don’t have to do it in slow Javascript). This file is only downloaded if the user clicks the “Search” button, as not to slowdown the pace of regular browsing or chew up data when it’s not required. I’m hoping the browser will automatically cache this file so it is not re-downloaded on subsequent searches.

The Network panel of the Chrome Developer Tools showing the time it takes to download the site's search dictionary (index.json) to the clients browser.
All-in-all, it was only about 4 hours effort to get the search feature to where it is now! It is the result of a small amount of HTML, Javascript and CSS embedded within the Hugo blog. For anyone who wants to use it for inspiration (or copy it, it’s open source!), it can be found in the following places:
- Static HTML: https://github.com/gbmhunter/blog/blob/master/layouts/_default/baseof.html
- Javascript: https://github.com/gbmhunter/blog/blob/master/static/js/fastsearch.js
- CSS: https://github.com/gbmhunter/blog/blob/master/static/css/style.css.
Other examples of static site search functionality can be found all over the web. Some examples include:
- http://meta.ath0.com/search/.
- The gohugo.com page “Search for your Hugo Website”.
- The gatsbyjs.org page “Adding Search” (note that this is for another popular static website building tool called Gatsby, not Hugo).
February 2020 Updates
Added the following information to the AWS S3 page:
aws s3 syncand the--exact-timestampsparameter.AWS S3’s data consistency model (including read after write and eventual consistency).
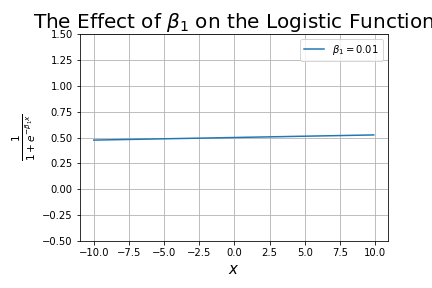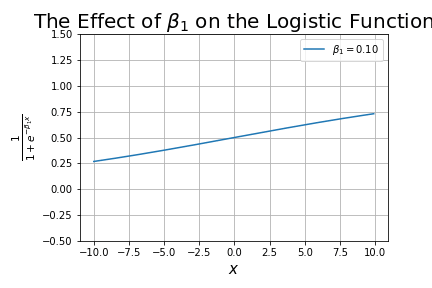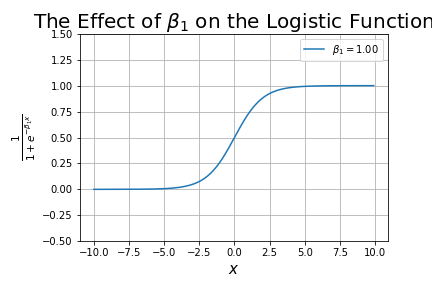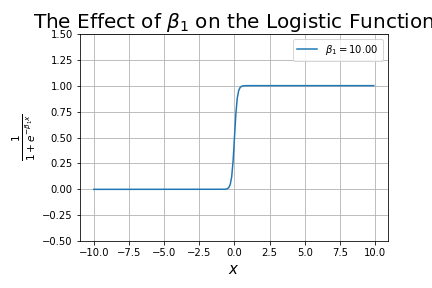
- Added a new tutorial on The Sigmoid Function, including the logistic function.

- Added a new tutorial on logistic regression (the logistic function being one type of Sigmoid function), called Understanding Logistic Regression
January 2020 Updates
Added the Happy New Year 2020 page, which compiles interesting blog statistics for the 2019 year.
Renamed all leaf nodes filenames from
_index.mdtoindex.md, as using the former led to the tag pages not being created.Information on handling warnings has been added to the Numpy page.
Updated the TSOC-6 Component Package page with more clarification on the differences between the different variants (D6+1, D6-1, D6N+1 and D6N-1).
Added a new QFP Component Package page, which will consolidate all of the variant information (e.g. TQFP) that existed on individual pages.
Updated many component package pages, including:
And also added the following packages to the component package database:
Switched the site title and content title around in the HTML page title, such that it is now:
<page title> | mbedded.ninaThis makes it easier to determine what the page is when you have a lot of tabs open on a tab-based browser such as Chrome or Edge.
Added cached external content to the How To Calculate Maximum Track Current page.
Added more specific information about dynamic memory allocation on embedded systems to the Dynamic Memory Allocation page.
Happy New Year 2020

A big happy new year to you from Geoff here at blog.mbedded.ninja. Looking back at this blog in 2019, below are some interesting statistics from the 2019 year.
Statistics for 2019
This is the second year in a row in which I have used Google Analytics for statistics.
Summary
| Year | No. Page Views | No. Users |
|---|---|---|
| 2017 | 83k | 41k |
| 2018 | 116k | 63k |
| 2019 | 99k | 49k |

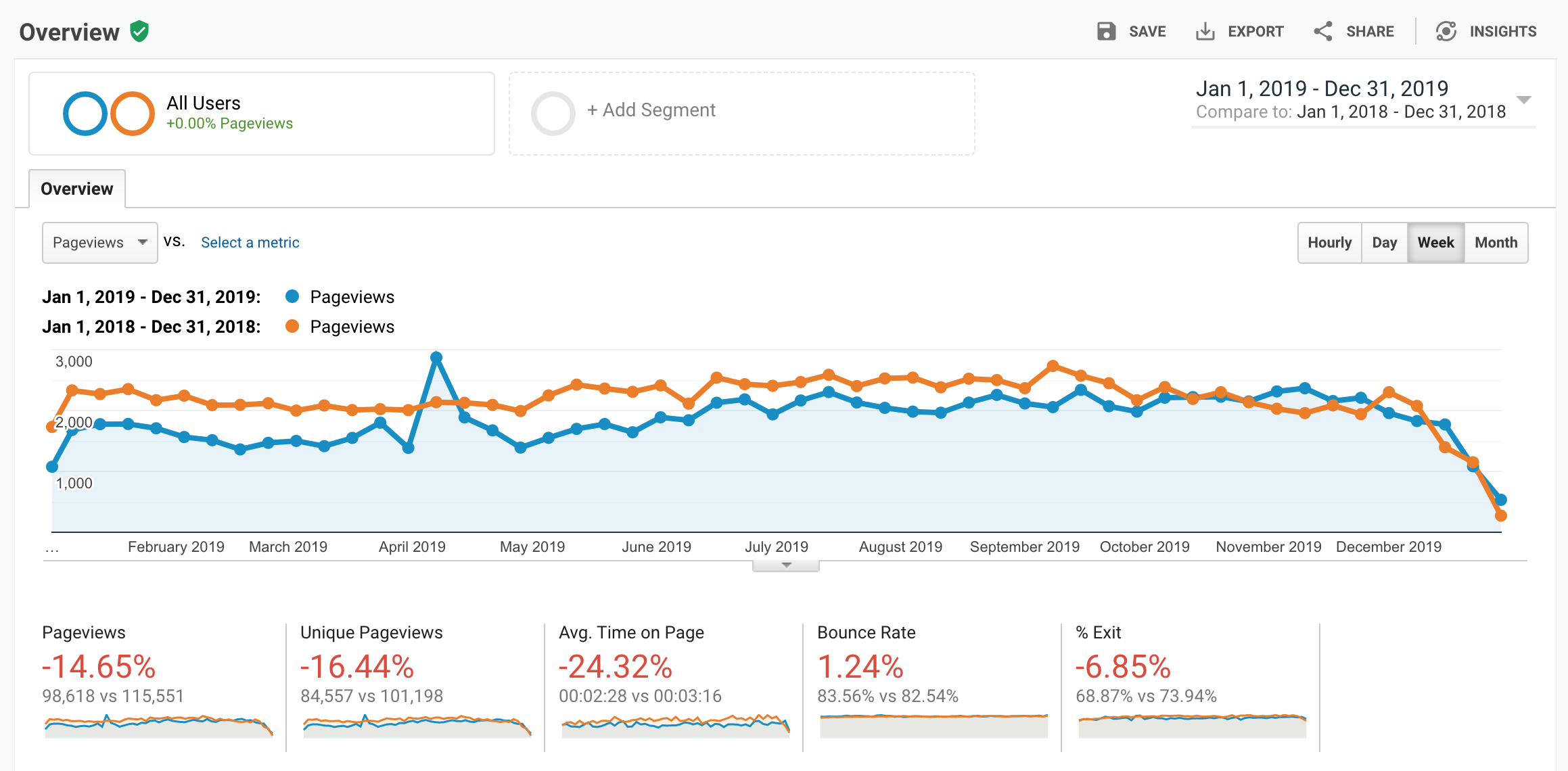
A comparison of the number of page views per week for the 2018 and 2019 years. Image from Google Analytics.

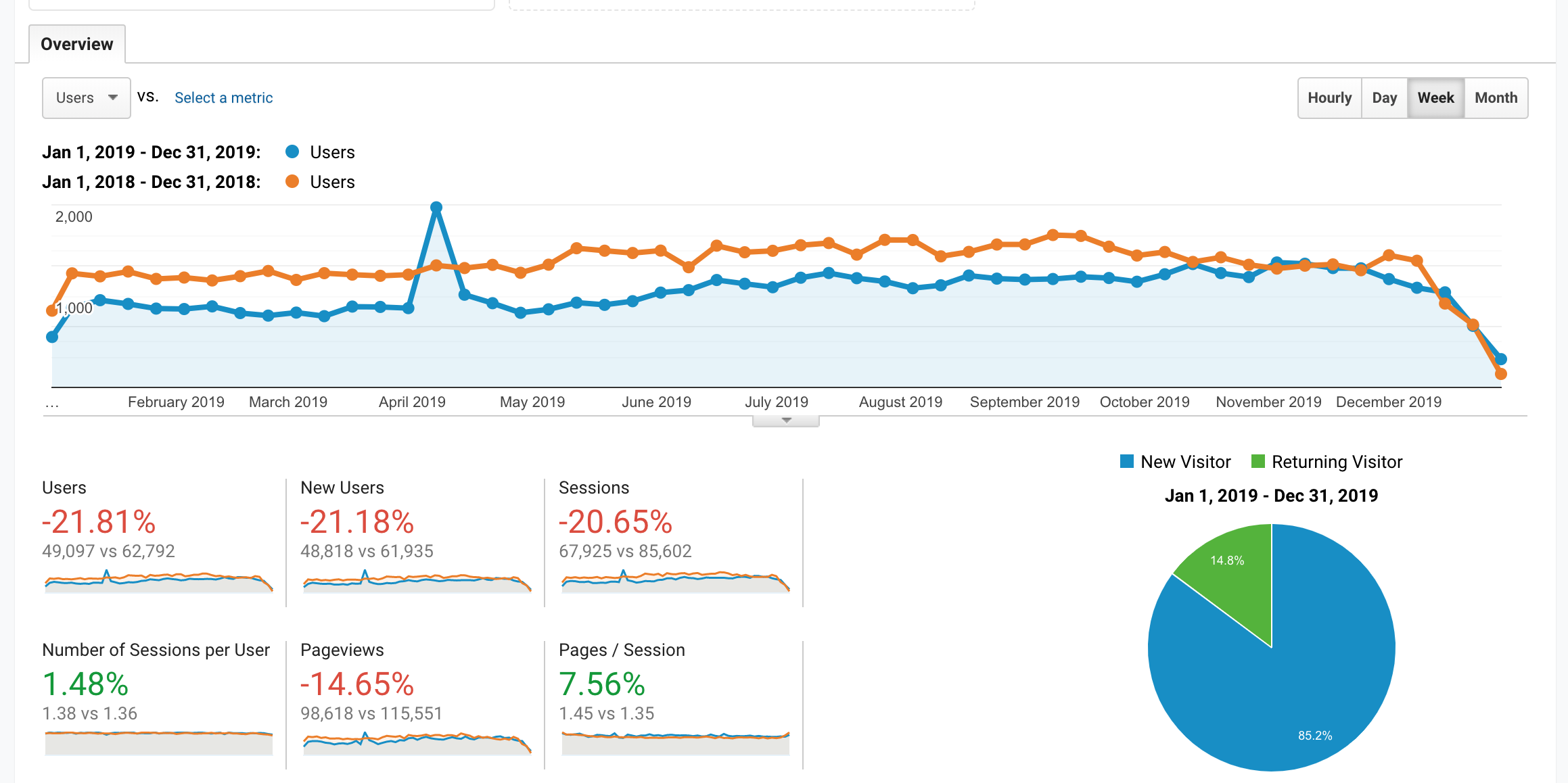
A comparison of the number of users per week for the 2018 and 2019 years. Image from Google Analytics.
A page view is a single view of a page (which can be a returning or new user). A user is a unique person who has visited this website at least once.
Most Popular Pages
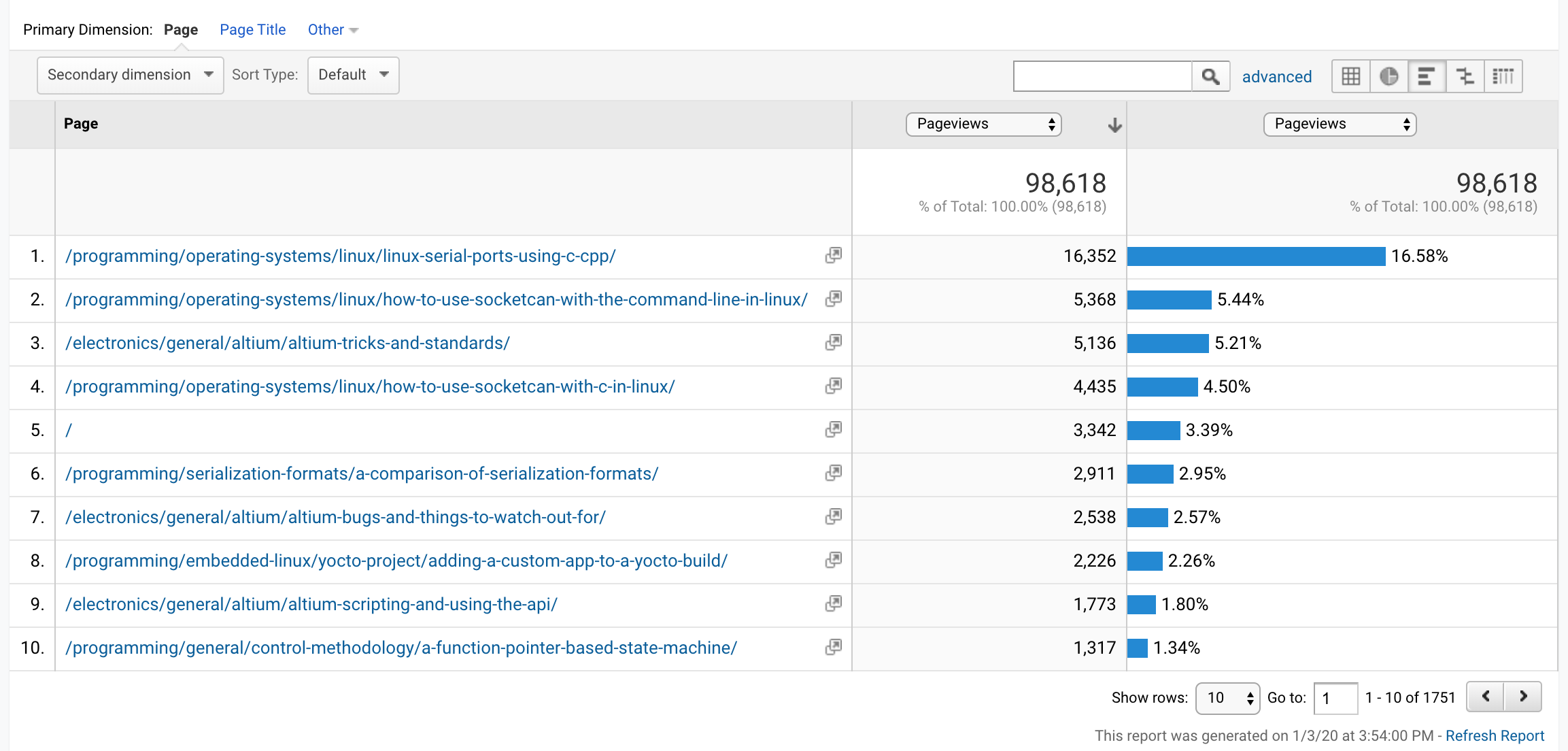
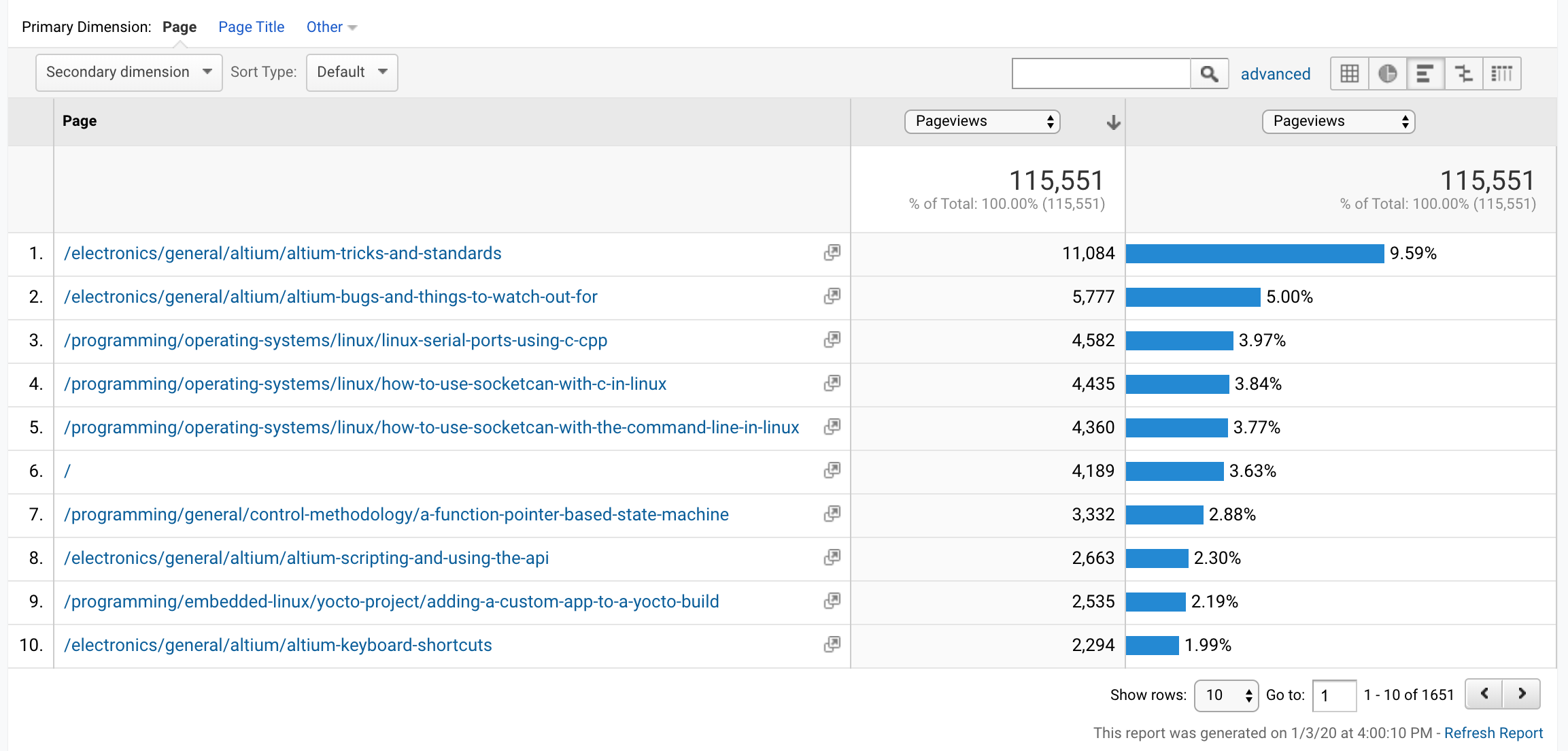
Ranked by number of page views:

Compared to the top 10 pages of 2018:

For the first time ever, we see Linux-related pages take over the top positions that were held by Altium-related pages for at least the last 5 years. There were no hugely different page categories that entered the top 10 list this year.
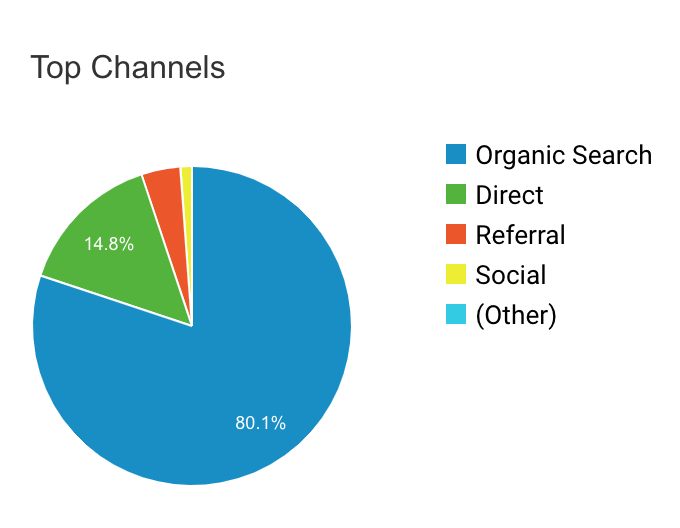
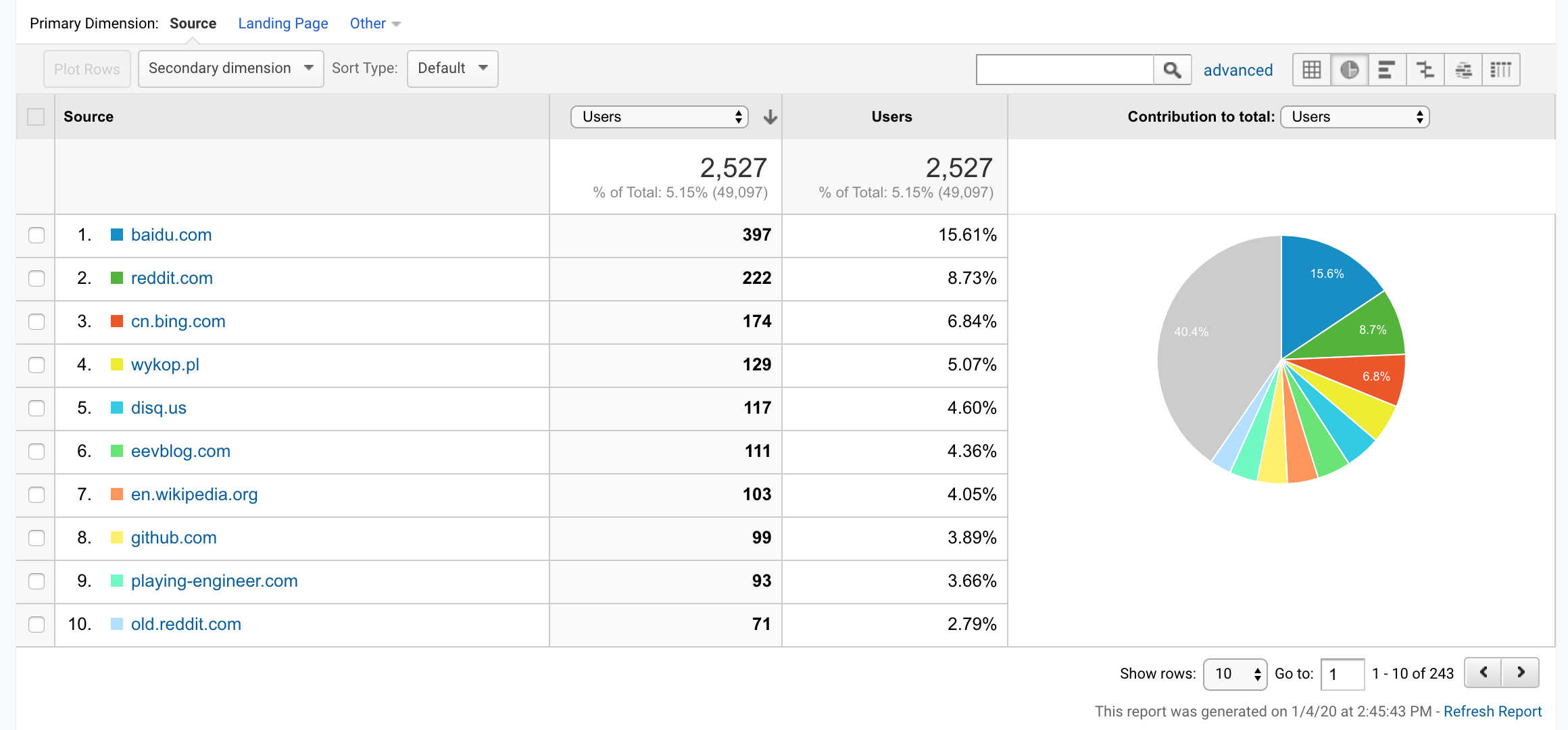
Acquisition

Most Popular Referrers

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Goal Completion
Looking back at the goals set at the start of 2019, most of them were fully completed!
- DONE: Utilize Hugo to it’s fullest capabilities. Although the migration from Wordpress to Hugo is complete, I feel like I have not yet explored all of the possibilities that Hugo allows. This includes sitemaps, RSS feeds, automatic thumbnail creation, better shortcodes, e.t.c.
- PARTIALLY DONE: Find a way to reliably detect dead links as they occur, along with an easy way of fixing them. This was enabled for internal links everytime the site is compiled (using a Hugo shortcode), but is harder to do for external links due to the amount of time/bandwidth required to check all the links.
- DONE: Move all of the mbedded.ninja GitHub repos into my own personal account, as there is no real need for a mbedded.ninja “organization” on GitHub, at it just leads to extra work and confusion on where repos are.
- DONE: Remove all the excess images in the blog repository. As a result of the Wordpress migration, there are many copies of a single image, each at a slightly different pixel size (I’m assuming they were created as part of a page load speed optimization in Wordpress). These are un-needed as Hugo can resize images at build time to correctly fit the container on the page. These extra images are just using up repo space.
- DONE: And of course, as always, add more content!
Plans For This Year
- Integrate more of the calculators at calc.mbedded.ninja into the pages of this blog (blog.mbedded.ninja).
calc.mbedded.ninjais not getting the exposure I first hoped. It could potentially be because of the SPA’s (Single Page Application) poor SEO (Search Engine Optimization), as it uses the Javascript framework Vue to render everything on the client side. Google’s search bots are meant to be able to handle indexing this sort of thing in 2019, but it still may be performing worse in the search rankings than it it was SSR (Server Side Rendered).